Research Projects
Reinforcement Learning
- Constrained Reinforcement Learning for Lane Keeping in Autonomous Driving: Lane keeping (LK) in self-driving cars or autonomous driving systems is a complex and challenging problem that requires a system to make a sequence of decisions in real-time. To tackle such sequential decision-making problems, reinforcement learning (RL) has emerged as the go-to approach. However, a key challenge in RL is the need for an appropriate reward function for the domain. LK is a multi-objective optimization problem that requires maximizing driving distance and minimizing lane deviations and collisions. To address this challenge, we formulate LK as a constrained RL problem, where we use driving distance as the reward and other objectives, such as lane deviations and collisions, as cost constraints. Under this framework, the weight coefficients are also automatically learned along with the policy, eliminating the need for scenario-specific tuning. We evaluate our approach on a popular autonomous driving platform called Duckietown in both simulation and real-world settings. Empirically, our approach outperforms various baselines on the Duckietown platform in terms of performance. Moreover, we have successfully transferred and validated our approach in real-world lane-keeping scenarios, which is crucial for demonstrating its practical value. [AAMAS-2025]
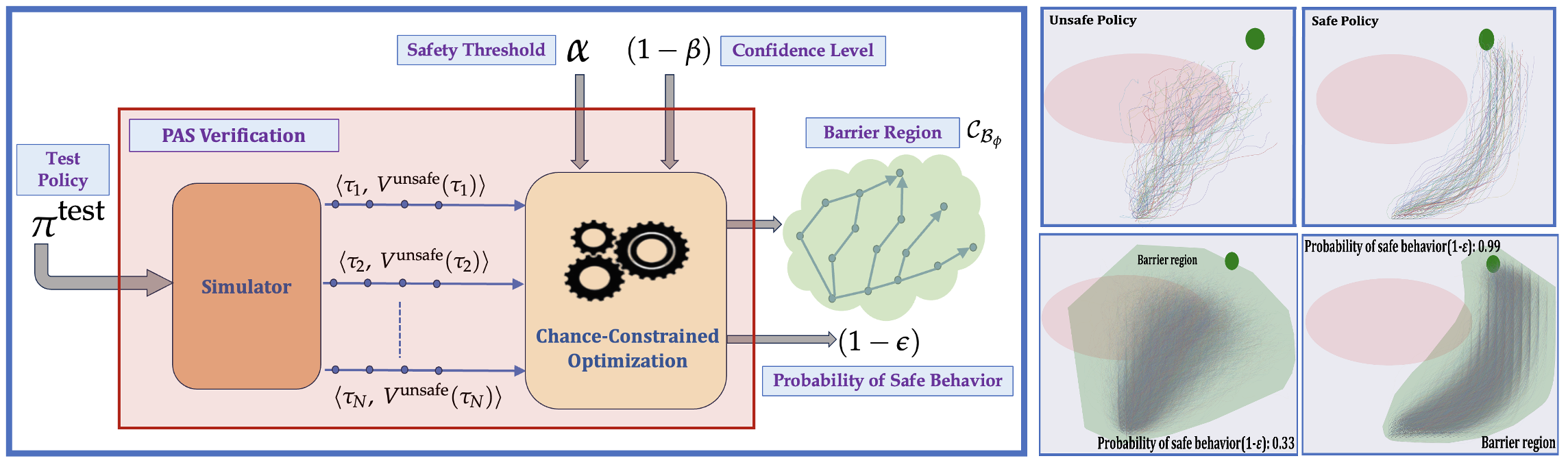
- Probably Approximate Safe RL Policy: With the advancement of machine learning based automation in the current digital world, the problem of safety verification of such systems is becoming crucial, especially in safety-critical domains like self-driving cars, robotics, etc. Reinforcement learning (RL) is an emerging machine learning technique with many applications, including in safety-critical domains. The classical safety verification approach of making a binary decision on determining whether a system is safe or unsafe is particularly challenging for an RL system. Such an approach generally requires prior knowledge about the system, e.g., the transition model of the system, the set of unsafe states in the environment, etc., which are typically unavailable in a standard RL setting. Instead, this paper addresses the safety verification problem from a quantitative safety perspective, i.e., we quantify the safe behavior of the policy in terms of probability. We formulate the safety verification problem as a chance-constrained optimization using the technique of barrier certificate. We then use a sampling based approach called scenario optimization to solve the chance-constrained problem, which gives the desired probabilistic guarantee on the safe behavior of the policy. Our extensive empirical evaluation shows the validity and robustness of our approach in three RL domains. [AAMAS-2024]
Large-Scale Multi-Agent Systems
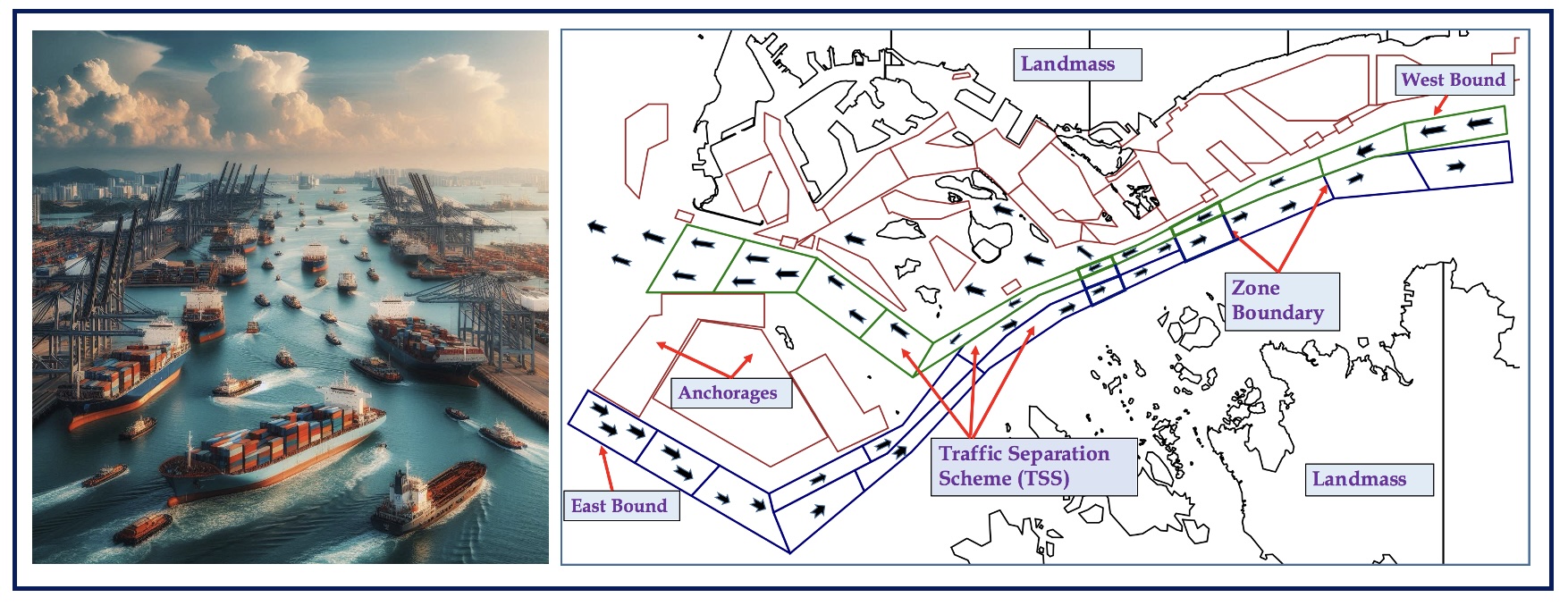
- Multi-agent RL for Maritime-Traffic Control: We address the problem of maritime traffic management in busy waterways to increase the safety of navigation by reducing congestion. We model maritime traffic as a large multiagent systems with individual vessels as agents, and the port authority as the regulatory agent. We develop a maritime traffic simulator based on historical traffic data that incorporates realistic domain constraints such as uncertain and asynchronous movement of vessels. We also develop a traffic coordination approach that provides speed recommendation to vessels in different zones. We exploit the nature of collective interactions among agents to develop a scalable policy gradient approach that can scale up to real world problems. Empirical results on synthetic and real world problems show that our approach can significantly reduce congestion while keeping the traffic throughput high. [AAMAS-2020, AAAI-2019]
- Multi-agent RL for Air-Traffic Control: Many real world systems involve interaction among large number of agents to achieve a common goal, for example, air traffic control. Several model-free RL algorithms have been proposed for such settings. A key limitation is that the empirical reward signal in model-free case is not very effective in addressing the multiagent credit assignment problem, which determines an agents contribution to the teams success. This results in lower solution quality and high sample complexity. To address this, we contribute (a) an approach to learn a differentiable reward model for both continuous and discrete action setting by exploiting the collective nature of interactions among agents, a feature commonly present in large scale multiagent applications; (b) a shaped reward model analytically derived from the learned reward model to address the key challenge of credit assignment; (c) a model-based multiagent RL approach that integrates shaped rewards into well known RL algorithms such as policy gradient, soft-actor critic. Compared to previous methods, our learned reward models are more accurate, and our approaches achieve better solution quality on synthetic and real world instances of air traffic control, and cooperative navigation with large agent population. [ICAPS-2021]